



Als wir das letzte Mal in unserem englischsprachigen Blog über die Produktkategorisierung sprachen, wurde Shopify von über 1 Million Händler:innen genutzt. Seitdem sind wir weiter gewachsen und bedienen heute Millionen von Händler:innen, die Milliarden von Produkten in einer Vielzahl von Branchen verkaufen. Angesichts dieses Zustroms neuer Händler:innen haben wir beschlossen, unser bestehendes Modell für die Produktkategorisierung neu zu bewerten.
In diesem Beitrag erläutern wir, wie wir unser Produktkategorisierungsmodell weiterentwickelt und modernisiert haben, um die Genauigkeit um 8 % zu erhöhen und gleichzeitig unsere Abdeckung zu verdoppeln. Wir wollen die Herausforderungen bei der Lösung dieses Problems und die technischen Kompromisse, die wir auf dem Weg dorthin eingegangen sind, näher beleuchten. Zum Schluss werden wir ein Produkt beschreiben, das derzeit von mehreren internen Teams und unserem Partner-Ökosystem verwendet wird, um abgeleitete Datenprodukte zu erstellen.
Inhaltsverzeichnis:
- Neubewertung des Modells für die Produktkategorisierung
- Warum ist die Produktkategorisierung so wichtig?
- Das Modell
- Training des Modells
- Modellinferenz und Vorhersagen
- Metriken und Leistung
Neubewertung des Modells für die Produktkategorisierung
Mit der Neubewertung unseres bestehenden Modells für die Produktkategorisierung wollen wir sicherstellen, dass wir verstehen, was unsere Händler:innen verkaufen, damit wir die besten Produkte zur Steigerung ihrer Umsätze entwickeln können.
Zu diesem Zweck haben wir zwei Kennzahlen von höchster Bedeutung berücksichtigt:
- Wie oft waren unsere Vorhersagen korrekt? Um diese Frage zu beantworten, haben wir uns die Präzision, Trefferquote und die Genauigkeit des Modells angeschaut. Dies sollte allen, die bereits Erfahrung mit Klassifizierungsmodellen für maschinelles Lernen haben, sehr vertraut sein. Der Einfachheit halber werden wir diese Gruppe von Kennzahlen mit dem Begriff "Genauigkeit" bezeichnen. Diese Kennzahlen werden mit einem Hold-Out-Set berechnet, um eine unverfälschte Messung zu gewährleisten.
- Wie oft geben wir eine Vorhersage ab? Unser bestehendes Modell filtert Vorhersagen unterhalb einer bestimmten Konfidenzschwelle heraus, um sicherzustellen, dass wir nur wirklich belastbare Vorhersagen treffen. Deshalb haben wir eine Messgröße namens "Abdeckung" definiert: das Verhältnis zwischen der Anzahl der Produkte mit einer Vorhersage und der Gesamtzahl der Produkte.
Zusätzlich zu diesen beiden Kennzahlen interessiert uns auch, wie diese Vorhersagen genutzt werden und ob wir die richtigen Zugriffsmuster und SLAs bereitstellen, um alle Anwendungsfälle zu berücksichtigen.
Ein Beispiel: Wir möchten unseren Kund:innen Vorhersagen in Echtzeit mit geringer Latenz zur Verfügung stellen.
Nachdem wir unser Modell anhand dieser Kennzahlen bewertet und die verschiedenen Datenprodukte, die wir erzeugen wollten, berücksichtigt hatten, beschlossen wir die Entwicklung eines neuen Modells, um weitere Verbesserungsmaßnahmen vorzunehmen. Als wir uns dem Problem näherten, erinnerten wir uns an die toten Winkel des bestehenden Modells. Dazu gehörten Dinge wie die ausschließliche Verwendung von Textmerkmalen für die Vorhersage sowie die Fähigkeit, nur Produkte in englischer Sprache zu verstehen.

Kostenloses Webinar: In 30 Minuten zum eigenen Onlineshop
Du willst selbst mal sehen, wie schnell du einen Shop aufsetzen kannst?
Der Shopify-Experte und leidenschaftliche Shop-Betreiber Adrian Piegsa zeigt dir, wie du dich anmeldest, eine Domain verknüpfst, Produkte auswählst und natürlich alle rechtlichen Vorgaben umsetzt.
Jetzt kostenlos teilnehmenWarum ist die Produktkategorisierung so wichtig?
Bevor wir das Modell besprechen, wollen wir noch einmal zusammenfassen, warum die Produktkategorisierung ein so wichtiges Anliegen ist.
Händler:innen verkaufen eine Vielzahl von Produkten auf unserer Plattform, wobei diese über verschiedene Vertriebskanäle verkauft werden. Wir glauben, dass der Schlüssel zur Entwicklung der besten Produkte für unsere Händler:innen im Verständnis der von ihnen verkauften Artikel liegt. Indem wir zum Beispiel alle von unseren Händler:innen verkauften Produkte in eine Standardkategorie einordnen, können wir Funktionen wie eine bessere Suche und Entdeckung über alle Kanäle hinweg sowie personalisierte Einblicke zur Unterstützung der Marketingbemühungen der Händler:innen entwickeln.
Lesetipp: Lerne Shopifys Fundament der Datenwissenschaft und Technik kennen, mit dem unsere internen Teams, Händler:innen und Partner:innen schnell gute Entscheidungen treffen können.
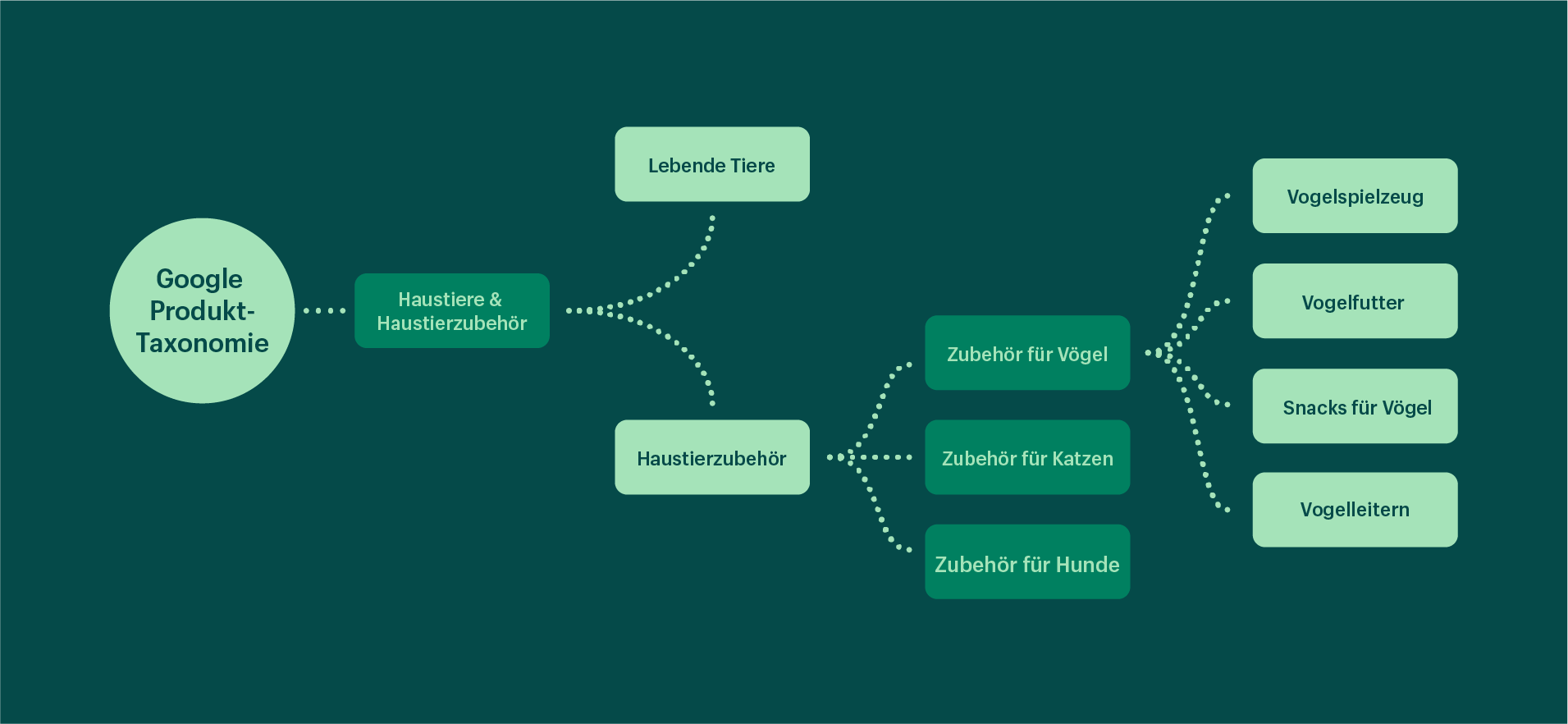
Unser aktuelles Kategorisierungsmodell verwendet die Google Produkt-Taxonomie (GPT). Die GPT ist eine Liste mit über 5.500 Kategorien, die uns bei der Organisation von Produkten helfen. Im Gegensatz zu einer herkömmlich flachen Kategorieliste, wie sie für die meisten Klassifizierungsprobleme üblich ist, zeichnet sich die GPT durch eine hierarchische Baumstruktur aus. Sowohl die schiere Anzahl der Kategorien in der Taxonomie als auch die komplexe Struktur und Beziehung zwischen den verschiedenen Klassen machen das Modellieren und Lösen dieses Problems schwierig.
Das Modell
Bevor wir uns an die Erstellung unseres optimierten Modells machen konnten, mussten wir zunächst die uns zur Verfügung stehenden Produktmerkmale erkunden. Unten findet sich ein Beispiel für die Seite zur Produktverwaltung, die du im Backend von Shopify-Händler:innen sehen kannst:
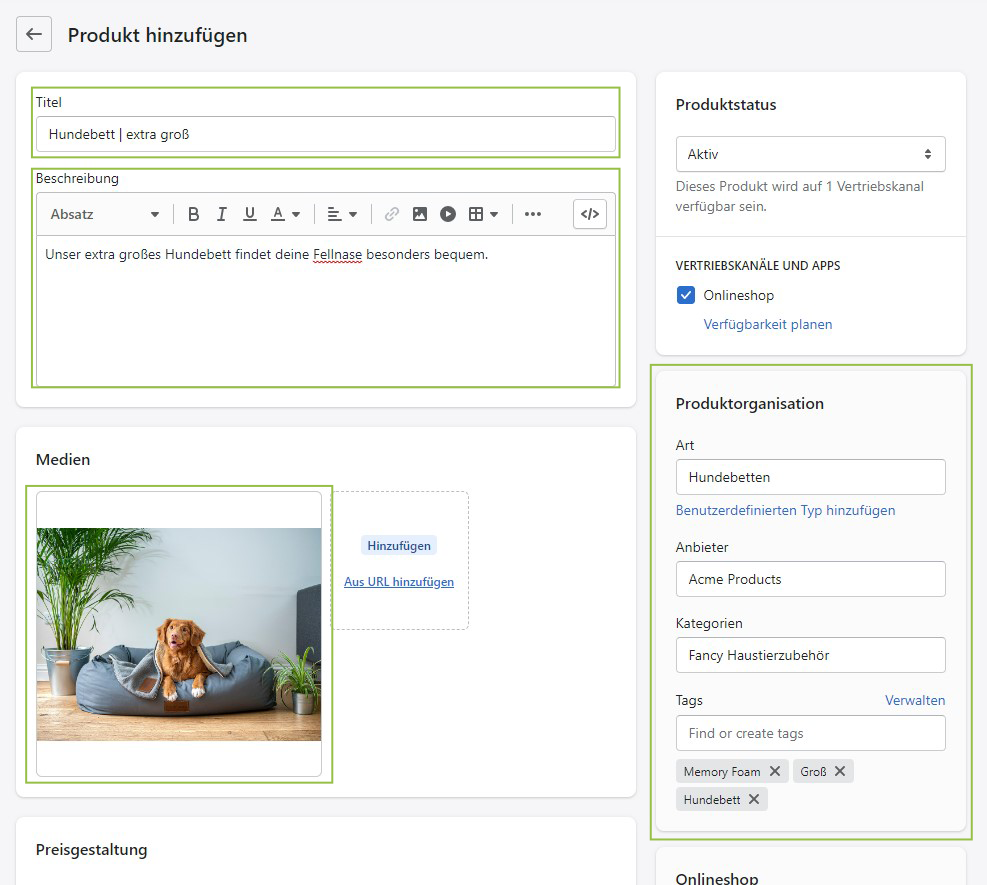
Das Bild oben zeigt die Seite für die Produktverwaltung im Shopify-Adminbereich. Wir haben die Merkmale hervorgehoben, die uns bei der Identifizierung des Produkts weiterhelfen können. Dazu gehören der Titel, die Beschreibung des Anbieters, die Sammlung der Produkttypen, die Tags und die Produktbilder.
Lesetipp: Shopify und Open Source: Eine für beide Seiten nützliche Beziehung
Wir haben zwar einige Merkmale, die uns bei der Identifizierung des Produkts helfen können, aber nichts in einem strukturierten Format. So können zum Beispiel mehrere Händler:innen, die dasselbe Produkt verkaufen, unterschiedliche Werte für den Produkttyp verwenden. Dies bietet den Händler:innen zwar viel Flexibilität bei der internen Organisation ihres Warenbestands, erschwert aber die Kategorisierung und Indexierung dieser Produkte über die verschiedenen Shops hinweg.
|
Text-Merkmale |
|
|
Visuelle Merkmale |
|
Das sind die Merkmale, mit denen wir die Produkte kategorisiert haben.
Vektorisierung der Merkmale
Wir haben mehrere vortrainierte Modelle ausprobiert, um zu bestimmen, welche Modelle für die Bild- und Texteinbettung eingesetzt werden sollten. Die zu berücksichtigenden Parameter waren sowohl die Modellleistung als auch der Berechnungsaufwand. Beim Abwägen dieser beiden Parameter einigten wir uns auf Folgendes:
- Mehrsprachiges BERT (Bidirectional Encoder Representations from Transformers) für Text
- MobileNet-V2 für Bilder
Lesetipp: Mit besseren Produktbeschreibungen mehr verkaufen. In diesem Blogbeitrag erhältst du 9 Tipps für effektive Beschreibungen deiner Produkte!
Architektur des Modells
Uns stellt die Kategorisierung hierarchischer Klassifizierungsprobleme vor zusätzliche Herausforderungen, die über ein einfaches Mehrklassenproblem hinausgehen. Aus den bisherigen Versuchen, dieses Problem zu lösen, haben wir zwei Lehren gezogen:
- Die Beibehaltung des Mehrklassencharakters dieses Problems ist bei der Erstellung von Vorhersagen von großem Vorteil. Zum Beispiel: Auf Ebene 1 der Taxonomie gibt es 21 verschiedene Klassenbezeichnungen im Vergleich zu mehr als 500 Bezeichnungen auf Ebene 3.
- Das Lernen der Parent-Nodes hilft bei der Vorhersage der Child-Nodes. Nehmen wir beispielsweise das Bild in unserem Beispiel der Shopify-Produktverwaltung: Hier ist es einfacher, das Produkt als "Hundebetten" vorherzusagen, wenn wir es bereits zuvor der Kategorie "Hundezubehör" zugeordnet haben.
Lesetipp: Wie du in 9 einfachen Schritten deinen Shopify Shop erstellen kannst, erfährst du hier. Außerdem gibt´s ein kostenloses E-Book zum Downloaden!
Also haben wir das Problem als Multi-Task- und Multi-Klassen-Klassifizierungsproblem formuliert, um diese Erkenntnisse in unser Modell einfließen zu lassen.
- Multi-Task: Jede Ebene der Taxonomie wurde als separates Klassifizierungsproblem behandelt. Dabei wurde die Ausgabe jeder Ebene wieder in das nächste Modell übertragen, um die Vorhersage für die nächste Ebene zu treffen.
- Multi-Klasse: Jede Ebene in der Taxonomie enthält eine unterschiedliche Anzahl von Klassen, sodass jede Aufgabe zu einem einzigen Mehrklassen-Klassifikationsproblem wurde.
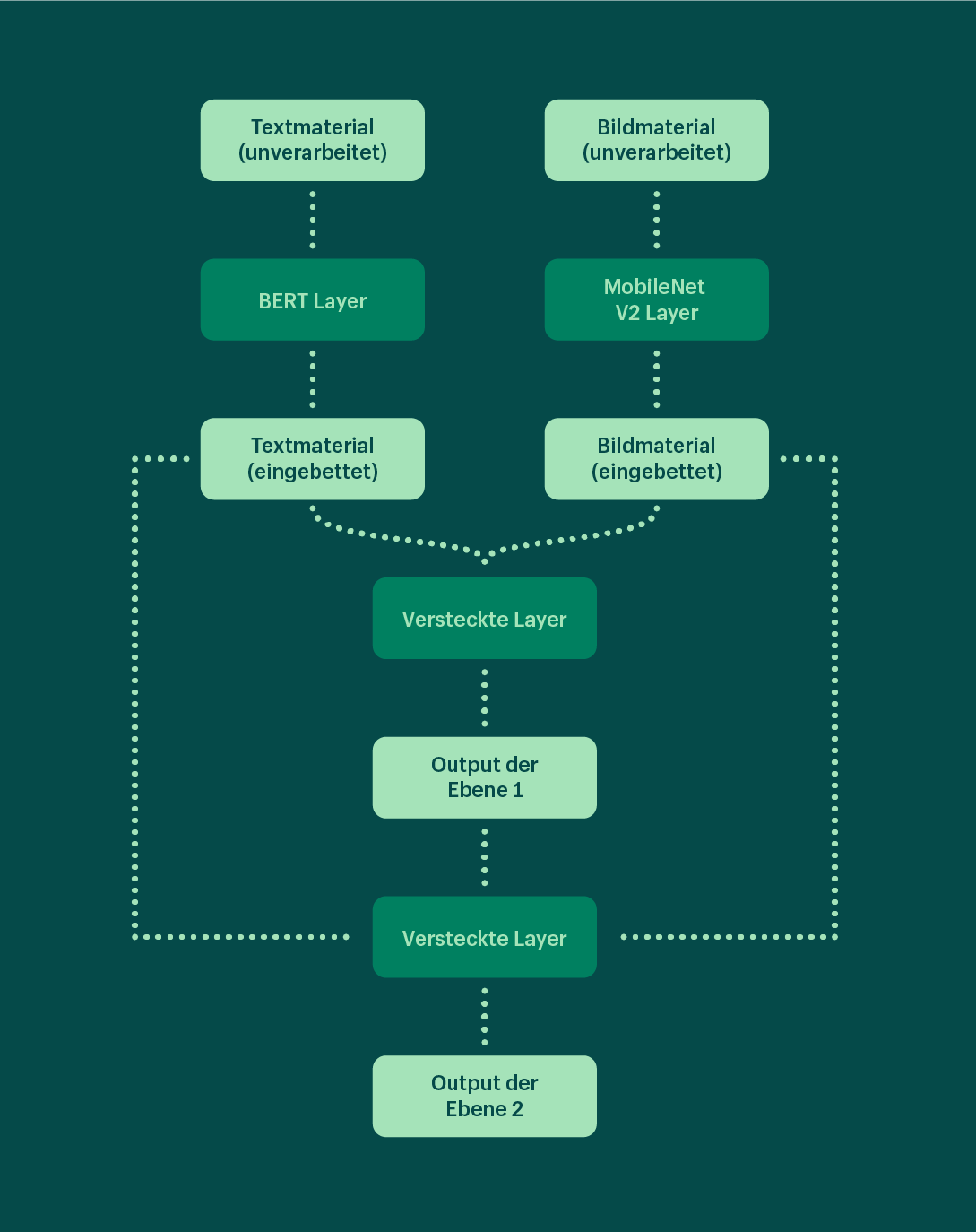
Das obige Bild zeigt den Ansatz, den wir zur praktischen Umsetzung dieser Lektionen gewählt haben. Wie bereits erwähnt, verwenden wir vortrainierte Modelle, um die unverarbeiteten Text- und Bildmerkmale einzubetten und dann die Einbettungen in mehrere versteckte Schichten zu übertragen, bevor wir eine Mehrklassen-Ausgabeschicht für die Vorhersage auf Ebene 1 haben. Die Ergebnisse dieser Schicht werden dann zusammen mit den ursprünglichen Einbettungen in die nachfolgenden versteckten Schichten eingegeben, um die Ergebnisse der Ebene 2 vorherzusagen. Diese Feedbackschleife setzen wir bis zur Ebene 7 fort.
Einige wichtige Punkte, die es zu beachten gilt:
- Wir haben insgesamt sieben Output-Layer, die den sieben Ebenen der Taxonomie entsprechen. Jede dieser Output-Layer ist mit einer eigenen Verlustfunktion verbunden.
- Während des Vorwärtsdurchlaufs des Modells beeinflussen die übergeordneten Nodes die Ausgaben der untergeordneten Nodes.
- Bei der Backpropagation werden die Verluste aller sieben Ausgabeschichten gewichtet kombiniert, um einen einzigen Verlustwert zu erhalten, der zur Berechnung der Steigungswerte verwendet wird. Das bedeutet, dass die Leistungen der unteren Ebenen die Gewichtung der höheren Ebenen beeinflussen und das Modell in die richtige Richtung lenken können.
- Obwohl wir die Vorhersagen der Parent-Nodes an die Vorhersagen der Child-Nodes weitergeben, um diese zu beeinflussen, legen wir keine strengen Bedingungen fest, dass die Vorhersage der Child-Nodes unbedingt ein Unterelement der Vorhersage der vorherigen Ebene sein muss. So kann das Modell z. B. Ebene 2 als "Haustierbedarf" vorhersagen, auch wenn es Stufe 1 als "Kunst & Unterhaltung" vorhergesagt hat. Dies lassen wir während des Trainings zu, damit korrekte Vorhersagen bei Child-Nodes falsche Vorhersagen am übergeordneten Parent-Node in die richtige Richtung lenken können. Auf diesen Punkt werden wir später im Rahmen der Inferenzphase noch einmal zurückkommen.
- In der Trainingsphase können wir Ungleichgewichte in den Klassen mithilfe von Klassengewichten ausgleichen. Unser Datensatz ist sehr unausgewogen. Das macht es uns schwer, einen Klassifikator zu trainieren, der verallgemeinert. Durch das Hinzufügen von Klassengewichten können wir die Auswirkungen des Klassenungleichgewichts abmildern. Zudem können wir damit Fehler bei der Vorhersage von Klassen, die weniger Stichproben haben, sanktionieren und so den Mangel an Beobachtungen in diesen Klassen ausgleichen.
Lesetipp: Hier findest du immer die neuesten Shopify-Updates sowie anstehende und vergangene Shopify-Events und Meetups.
Training des Modells
Einer der Vorteile der Größe von Shopify ist die Verfügbarkeit großer Datensätze, um herausragende Datenprodukte zu erstellen, die unseren Händler:innen und ihren Kund:innen zugutekommen. Für die Produktkategorisierung haben wir Hunderte von Millionen Beobachtungen zusammengetragen, aus denen wir lernen können. Aber das bringt auch eine Reihe von Herausforderungen mit sich! Das von uns oben beschriebene Modell erweist sich als äußerst komplex. Am Ende beinhaltet es über 250 Millionen Parameter. Hinzu kommt die Größe unseres Datensatzes, sodass es eine große Herausforderung ist, dieses Modell in einer angemessenen Zeit zu trainieren. Das Training dieses Modells auf einem einzigen Rechner kann selbst mit GPU-Auslastung mehrere Wochen dauern. Wir mussten also die Trainingszeit verkürzen, ohne die Leistung des Modells zu beeinträchtigen.
Zur Lösung dieses Trainingsproblems haben wir uns für einen Ansatz der Datenparallelisierung entschieden. So können wir den Trainingsprozess beschleunigen, indem wir den Trainingsdatensatz in Gruppen aufteilen und für jede Gruppe einen Rechner zum Trainieren des Modells verwenden. Das Modell wurde mit verteiltem Tensorflow unter Verwendung mehrerer Worker und GPUs auf der Google Cloud Platform erstellt und trainiert. Wir haben mehrere Optimierungen vorgenommen, um sicherzustellen, dass wir diese Ressourcen so effizient wie möglich nutzen.
Weitere Tipps und Tricks für Entrepreneure haben unsere Podcast-Gäste für dich. Hör rein!
Modellinferenz und Vorhersagen
Wie im Abschnitt über die Modellarchitektur beschrieben, zwingen wir das Modell nicht dazu, sich im Rahmen des Trainings streng an die Hierarchie zu halten. Dieser Ansatz funktioniert während des Trainings. Doch während der Inferenzzeit können wir ein solches Verhalten nicht zulassen, da dies eine zuverlässige und reibungslose Erfahrung für die Kund:innen gefährden würde. Um das Problem zu lösen, bauen wir eine zusätzliche Logik in den Inferenzschritt ein. Die Schritte bei der Vorhersage sind:
- Erstellen von unbearbeiteten Vorhersagen anhand des trainierten Modells. Das Ergebnis sind sieben Felder mit Konfidenzwerten. Jedes Feld steht für eine Ebene der Taxonomie.
- Auswahl der Kategorie mit dem höchsten Konfidenzwert auf Stufe 1 und Benennung dieser Kategorie als Ebene-1-Vorhersage.
- Sammlung aller unmittelbaren Ableger der Ebene-1-Vorhersage. Daraus wählen wir das Child-Element mit dem höchsten Vertrauenswert aus und bezeichnen es als Ebene-2-Vorhersage.
- Diesen Prozess setzen wir fort, bis wir die Vorhersage der Ebene 7 erreichen.
Wir führen die obige Logik als Tensorflow-Operationen aus und entwickeln ein Keras-Unterklassenmodell, um diese Operationen mit dem trainierten Modell zu kombinieren. Dies ermöglicht uns die Verwendung eines einzigen Tensorflow-Modellobjekts, das die gesamte Logik sowohl für die Batch- als auch für die Online-Inferenz enthält.
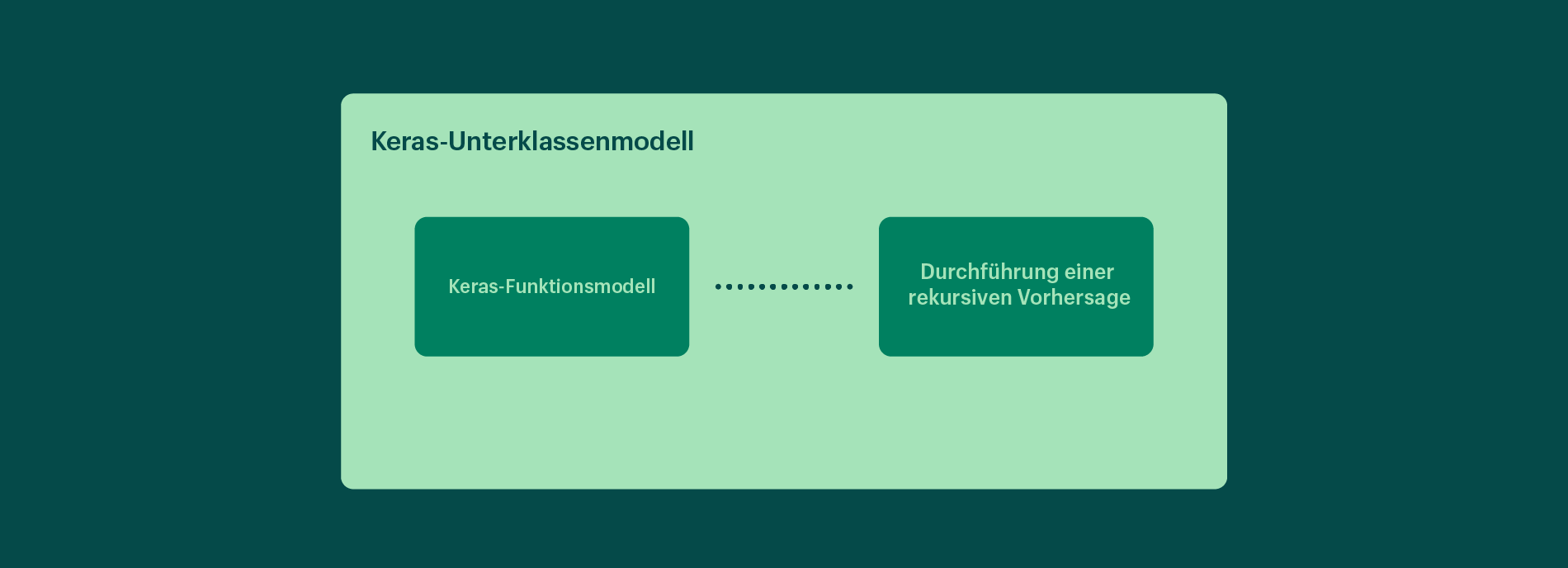
Das obige Bild zeigt, wie wir ein Keras-Unterklassenmodell erstellen, um das trainierte Keras-Funktionsmodell mit einem nachgeschalteten Tensorflow-Graphen zu verbinden und die rekursive Vorhersage durchzuführen.
Lesetipp: In diesem Leitfaden erfährst du, wie Preorders funktionieren.
Metriken und Leistung
Wir haben eine Reihe verschiedener Metriken zusammengetragen, um die Leistung eines hierarchischen Klassifizierungsmodells zu messen. Dazu gehören:
- Hierarchische Genauigkeit
- Hierarchische Präzision
- Hierarchische Trefferquote
- Hierarchisches F1
- Abdeckung
Zusätzlich zu den oben genannten Verbesserungen klassifiziert das neue Modell Produkte in mehreren Sprachen und ist nicht nur auf Produkte mit englischem Text beschränkt. Und das ist für uns und die Mission von Shopify, den Handel für alle Menschen auf der ganzen Welt besser zu machen, sehr wichtig.
Um sicherzustellen, dass nur die hochwertigsten Vorhersagen ausgegeben werden, legen wir unterschiedliche Schwellenwerte für die Konfidenzwerte auf verschiedenen Ebenen fest, um Vorhersagen mit geringer Konfidenz herauszufiltern. Das bedeutet, dass nicht alle Produkte auf jeder Ebene Vorhersagen aufweisen.
Ein Beispiel dafür ist in der folgenden Abbildung zu sehen:

Die Abbildung oben zeigt, wie das Foto des Hundebetts zu vier Ebenen von Vorhersagen führt. Die ersten drei Ebenen haben alle einen hohen Konfidenzwert und werden ausgewiesen. Die Vorhersage der vierten Ebene hat einen niedrigen Konfidenzwert und wird daher nicht dargestellt.
Lesetipp: Erfahre, wie Airsign durch Segmentierung und Kundendaten von Shopify eine effektivere Kundenansprache und die Reduktion der Versandkosten gelingt.
In diesem Beispiel belassen wir es bei der dritten Ebene der Vorhersagen, da die vierte Ebene nicht unserer minimalen Konfidenzforderung entspricht.
Dabei haben wir gelernt, wie wir das Modell so abstimmen können, dass diese verschiedenen Kennzahlen optimal aufeinander abgestimmt sind. So könnten wir zum Beispiel eine höhere hierarchische Genauigkeit auf Kosten einer geringeren Abdeckung erreichen. Das sind schwierige Entscheidungen, die wir nur treffen können, wenn wir unseren Geschäftszweck und die Prioritäten verstehen. Wir können gar nicht genug betonen, wie wichtig es ist, dass wir uns bei unserer Arbeit an den Anwendungsfällen und der Erfahrung der Händler:innen orientieren. Im Rahmen unserer Optimierungen haben wir uns auf die Verringerung negativer Erfahrungen und Reibungsverluste für Händler:innen konzentriert. Die Kennzahlen sind sicherlich ein guter Indikator für die Leistung des Modells. Wir haben aber auch Stichproben und eine manuelle Qualitätssicherung unserer Vorhersagen durchgeführt, um Problembereiche zu identifizieren.
Ein Beispiel dafür ist, wie wir die Leistung des Modells in sensiblen Kategorien wie "Religiöses und Zeremonielles" genau unter die Lupe genommen haben. Auch wenn die Gesamtkennzahlen gut aussehen, können sie die Leistung des Modells in kleinen Teilbereichen der Taxonomie verschleiern. Und dies kann zu großen Beeinträchtigungen bei den Händler:innen führen. Wir haben die Schwellenwerte für die Konfidenzwerte manuell angepasst, um in diesen sensiblen Bereichen eine besonders hohe Leistung zu gewährleisten. Wir empfehlen, diese Praxis bei der Einführung von Datenprodukten, die auf maschinellem Lernen basieren, ebenfalls anzuwenden.
Lesetipp: Hier haben wir die 7 meistgestellten Fragen zu Shopify in Deutschland vom Shopify-Experten Patrick Rosenblatt beantworten lassen.
Wie geht es jetzt weiter?
Durch das Upgrade des Vorgängermodells konnten wir sowohl die Präzision als auch die Abdeckung verbessern. Insgesamt konnten wir die Genauigkeit um acht Prozent erhöhen und gleichzeitig die Abdeckung fast verdoppeln. So haben wir jetzt weitaus genauere Vorhersagen für viel mehr Produkte. Wir haben das Modell verbessert und ein zuverlässiges Produkt entwickelt, von dem unsere Händler:innen profitieren. Allerdings glauben wir, dass wir es noch weiter optimieren können. Zu den Verbesserungsbereichen gehören:
- Qualität der Daten: Wir haben einen umfangreichen Datensatz mit gekennzeichneten Produkten, der jedoch ein hohes Ungleichgewicht aufweist. Wir können die Unausgewogenheit des Datensatzes mit einer Reihe bekannter Techniken wie Klassengewichtung und Over-/Undersampling angehen. Gleichzeitig sind wir jedoch der Meinung, dass wir in Bereichen, in denen wir derzeit nicht genug Daten haben, neue Datenpunkte erheben sollten. Mit dem Wachstum von Shopify stellen wir fest, dass die von unseren Händler:innen verkauften Produkte von Tag zu Tag vielfältiger werden. Das bedeutet, dass wir weiterhin Daten in diesen neuen Kategorien und Abschnitten der Taxonomie erfassen müssen.
- Funktionen auf Händlerebene Das derzeitige Modell konzentriert sich auf die Merkmale auf Produktebene. Das ist zwar der offensichtlichste Ansatzpunkt, aber es gibt auch viele Signale, die nicht unbedingt auf die Ebene der einzelnen Produkte gehören, sondern auf die Händlerebene übertragen werden und uns bei der Erstellung besserer Vorhersagen helfen können. Ein einfaches Beispiel dafür ist ein hypothetischer Händler namens "Acme Shoe Warehouse". Es ist klar, dass der Name dieses Shops stark darauf hindeutet, was das in diesem Shop verkaufte Produkt sein könnte.
Bist du bereit deine Idee zum Leben zu erwecken?
Teste Shopify kostenlos und verkaufe, wo du willst!
Weiterlesen
- Wie du das meiste aus deinen Wochenenden herausholst, um eine Geschäftsidee zu verwirklichen
- Kleidung fotografieren- Der ultimative Foto-Guide für Bekleidungsprodukte
- Traffic aber kein Umsatz? Wie du deinen Shop untersuchen und optimieren kannst
- Mach ganz gewöhnliche Dinge außergewöhnlich gut
- Private Label- So baust du ein Business mit bewährten Produkten auf
- Mobile Shopping- Das Kaufhaus in der Hosentasche wächst immer weiter
- Nebenjobs- So kannst du 1.000 Euro (und mehr) im Monat dazu verdienen
- Firmennamen- So findet ihr den besten für euer Business
- Online-Marktplätze- Beliebter Vertriebskanal im Multichannel-Zeitalter
Häufig gestellte Fragen zu Rich-Image- und Textdaten zur Produktkategorisierung
Warum ist eine Produktkategorisierung wichtig?
Was ist besser am neuen Produktkategorisierungsmodell von Shopify?
Wie funktioniert das neue Produktkategorisierungsmodell von Shopify?
Wenn du dich für die Lösung komplexer Probleme in großem Maßstab begeisterst und gerne mehr lernen möchtest, stellen wir immer wieder neue Mitarbeiter:innen ein! Melde dich bei uns oder bewirb dich auf unserer Karriereseite.

